
9 interesting Google patents from 2023 and what they mean for SEO
18 min read
Google patents offer valuable insights into the search engine giant’s latest innovations and priorities for improving search technology.
This article dives into nine interesting Google patents from 2023, analyzing their potential implications for the future of SEO.
Do the patents reflect Google’s actual practices?
Just because Google files and publishes a patent application doesn’t guarantee that the methods outlined will be implemented in Google Search.
To gauge if Google finds a methodology or technology compelling enough to use in practice, you can check if the patent is pending in the U.S. and other countries.
A claim for patent priority in other countries must be made within 12 months of the initial filing.
Even if a patent doesn’t directly translate into practice, examining Google’s patents is valuable. It provides insights into the subjects and challenges Google’s product developers focus on.
(Note: This article only covers Google patents also published outside the U.S. The patents are listed in no particular order.)
1. Search result filters from resource content
- Identifier: US11797626B2
- Countries: U.S., China, Europe, Russia
- Publication date: October 2023
Google Search is getting even smarter with more filters to refine searches. This new patent could be a foundation for filter methodology.
The patent outlines a system designed to enhance search experiences by dynamically generating search query filters tailored to the content of resources (like webpages) relevant to a user’s query. This approach aims to improve the relevance and diversity of search options.
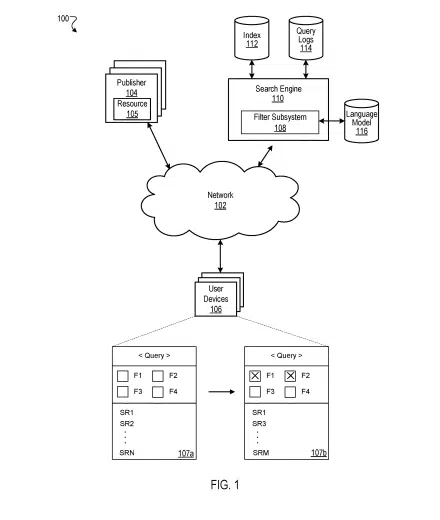
Concept overview
- Data processing: The system begins by analyzing a user’s search query to pinpoint relevant resources such as web pages or documents.
- Keyword extraction: Upon identifying pertinent resources, it then extracts key terms from their content. These keywords reflect the primary subjects or themes within the resources. For instance, a search for “best smartphones 2023” might yield keywords like “battery life,” “camera quality,” and “5G support.”
- Filter selection: The system refines these extracted keywords into a set of query filters. It employs criteria like diversity and difference thresholds to ensure each filter offers a unique perspective on the search results. Consequently, filters such as “Best Camera Phones,” “5G Smartphones,” and “Long Battery Life Phones” are formed, each directing to distinct search result subsets.
- User interaction: These query filters are then presented alongside their search results. This feature allows users to refine their searches further based on specific interests. The filters are dynamic, changing in response to the search query and the content of the currently available resources. For example, in the smartphone search scenario, selecting the “Best Camera Phones” filter would narrow down the results to focus on phones with superior camera quality.
This system provides a refined, user-focused search experience by:
- Processing search queries.
- Extracting relevant keywords.
- Creating diverse filters.
- Allowing dynamic user interaction with these filters.
SEO implications
Understanding the nuances of these dynamic search filter systems is essential for SEOs. It highlights the need to craft varied, rich and relevant content that aligns well with the potential search filters.
This alignment enables websites to effectively position themselves in search results, catering to users’ varied interests and queries.
- Emphasis on diverse and relevant content: SEO strategies must focus on developing content that encompasses a broad spectrum of pertinent topics within a given field. This approach will likely influence the dynamic filters a search engine might generate, enhancing the website’s visibility.
- Keyword optimization: A deep understanding of a specific domain’s most relevant and varied keywords is more critical than ever. These keywords will likely shape the search filters, making them a key factor in how Google discovers and ranks content.
- Aligning with user intent: SEO efforts should pivot toward a keen understanding and fulfillment of user intent. As search engines increasingly focus on dynamically catering to user intents through filters, aligning with these intents becomes a strategic necessity.
- Staying on top of emerging trends: Keeping abreast of emerging keywords and trends in a particular domain is crucial. These emerging elements could swiftly be incorporated into the dynamic filters, affecting search result relevance.
- Enhancing user engagement: Websites should strive to offer comprehensive and varied information. This engages users more effectively and potentially impacts how they appear in the filtered search results, influencing their overall search visibility.
2. Evaluating an interpretation for a search query
- Identifier: US20230334045A1
- Countries: U.S., China, South Corea, Europe
- Publication date: October 2023
Identifying the meaning and intent of a query is critical for search engines. This patent could be part of the methodology.
The patent notably includes a reference to BERT (Bidirectional Encoder Representations from Transformers), suggesting that this methodology could be relevant to BERT’s application in Search algorithms.
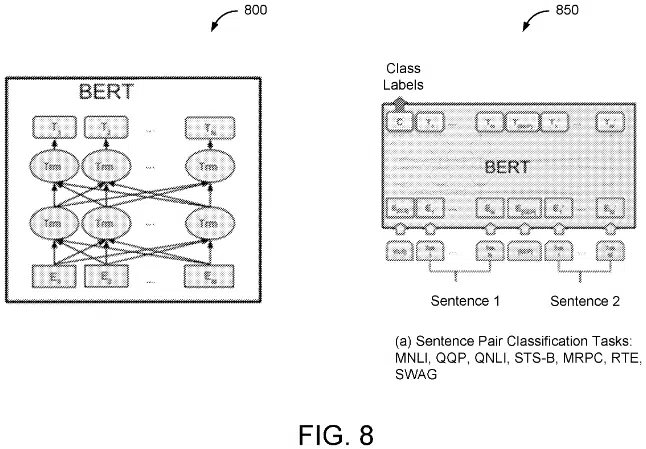
The patent outlines a system and method for assessing the accuracy of human interpretations of search queries, which incorporates two distinct models:
- First model: This is trained on a dataset that includes historical search queries, their human interpretations, and labels assigned by humans that indicate the accuracy of these interpretations. Its primary function is to determine the accuracy of a human interpretation of a search query.
- Second model: Building upon the initial assessment made by the first model, this model integrates additional factors such as time-related and cluster characteristics of the search query. Its role is to provide a final judgment on the accuracy of the human interpretation of the search query.
The Google patent delves into the concept of grouping or clustering search queries, a key aspect of its methodology for assessing interpretations of search queries.
The patent incorporates the concept of search intent, even though it might not explicitly mention the term “search intent.”
The patent’s focus on the accuracy of human interpretations of search queries inherently involves discerning the user’s intended purpose or goal behind their query, which is the essence of search intent.
Concept overview
Here’s an overview of how the patent implicitly addresses search intent.
Human interpretation of search queries
- The system’s evaluation of the accuracy of human interpretations of search queries inherently requires understanding the user’s intended meaning or goal.
- This understanding is central to the concept of search intent.
Search query refinements
- The patent discusses the identification of subsequent search queries as refinements of previous ones.
- This process is intrinsically linked to search intent, as users often refine their searches when initial results don’t fully satisfy their intent, leading to adjustments in their queries for more precise results.
Temporal and cluster features
- By considering temporal and cluster features in the evaluation process, the system indirectly deals with the context and nuances of search intent.
- For example, the timing of queries or their grouping within specific thematic clusters can provide insights into the users’ intended objectives.
Training dataset with human-evaluated labels
- The inclusion of human interpretations and evaluated labels for past search queries in the training dataset indicates that the system learns from previous instances where human judgment was used to understand the intent behind a query.
Vector sentence representations and distance algorithms
- The use of vector sentence representations and distance algorithms in parsing and grouping queries relates to understanding search intent.
- These technologies aid in comprehending the semantic meanings and subtleties of queries, which is crucial for discerning user intent.
SEO implications
- Emphasis on accurate query interpretation: SEO strategies should prioritize aligning content with users’ likely interpretations of search queries. Understanding and matching the anticipated user query interpretations is crucial for effective SEO.
- Importance of context and temporality: Content must be optimized considering the temporal context and potential clustering of topics or keywords. This approach ensures that the content remains relevant and accurately indexed based on emerging trends and time-sensitive queries.
- Adaptation to search refinements: Optimizing websites to suit refined searches is important, as these refinements may indicate initial misunderstandings or misinterpretations by search engines. A focus on catering to refined search queries can enhance a site’s relevance and accuracy in search results.
- Leveraging natural language processing (NLP): With the integration of methodologies like BERT, incorporating NLP strategies in content creation becomes increasingly important. This alignment with search engines’ query interpretation methods can improve a site’s visibility and relevance in search results.
3. Providing search results based on a compositional query
- Identifier: US11762933B2
- Countries: U.S., Europe, China
- Publication date: September 2023
Google is increasingly evolving Search into an entity-based search engine. Therefore, it is crucial to deliver relevant results according to entities.
This patent could be a piece of the puzzle to better understand entities and their relationships.
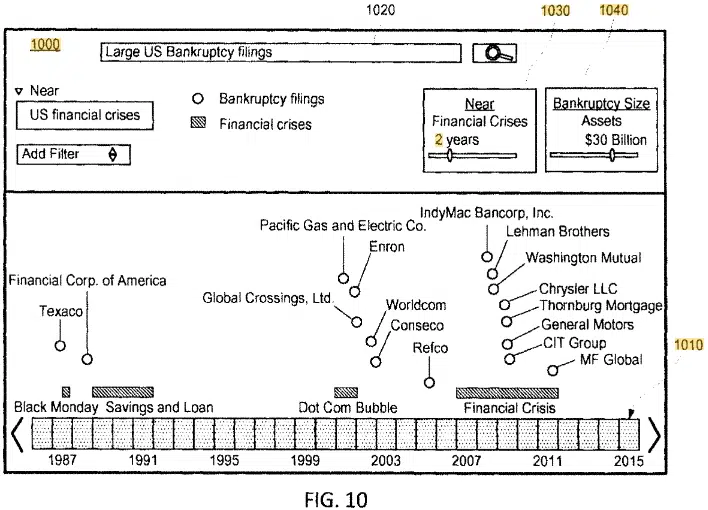
The patent details a technique for delivering search results based on compositional queries. This method includes:
- Recognizing entity types and their relationships within the query.
- Pinpointing nodes within a knowledge graph.
- Assessing attribute values to determine the resulting entity references.
This system is adept at managing queries that entail relative relationships among various entity types, offering search results that are more pertinent and contextually relevant.
Compositional queries involve queries encompassing multiple entity types and their interrelations.
Unlike queries centered on a single keyword or entity, compositional queries strive to interpret and generate results based on how different entities in the query relate to one another.
Concept overview
- Multiple entity types: Compositional queries include references to at least two different types of entities. An entity here refers to anything distinct, unique, and well-defined, like a person, place, object, concept, etc.
- Relative relationships: The entities within these queries are linked through some relative relationship. These relationships might be spatial, temporal, or other types of connections that specifically tie the entities together meaningfully.
SEO implications
- Complex query handling: SEO experts should note that search engines are likely advancing toward more sophisticated handling of queries that involve the interplay between various entities. This evolution necessitates a deeper understanding of optimizing content for these complex query structures.
- Knowledge graph optimization: Given the patent’s focus on utilizing a knowledge graph, optimizing content to be accurately recognized and categorized within these graphs is imperative. Effective integration into knowledge graphs can significantly enhance content visibility and relevance.
- Entity recognition: Structuring content in a manner that facilitates easy recognition and categorization of different entities and their relationships by search engines is essential. Clear and logical information organization can improve the content’s discoverability and relevance in search queries involving multiple entities.
- Contextual relevance: SEO strategies should prioritize ensuring that content is contextually relevant. This involves considering the search engine’s capability to comprehend and compare the attributes of different entities, thus aligning content strategy with the engine’s advanced interpretative abilities.
4. Contextualizing knowledge panels
- Identifier: US11720577B2
- Countries: U.S., Japan, South Korea, China, Germany, Europe
- Last publishing date: August 2023
Knowledge panels are the window into the Google knowledge graph and the stored entities.
Serving relevant and correct information according to entities is crucial. These panels are integrated with standard search results, offering a comprehensive information source. This patent discusses methods for handling this task.
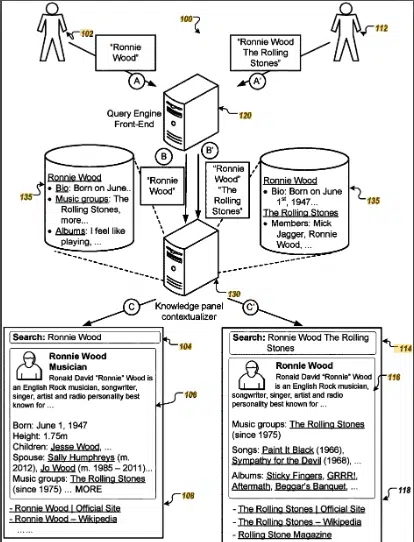
The patent focuses on methods, systems, and apparatus for enhancing search engine results by incorporating knowledge panels that provide contextual information related to search queries.
These knowledge panels are generated based on identifying entities (like singers, actors, and musicians) and context terms within user search queries.
- Entity identification: The system identifies entities referenced in a search query.
- Context terms: It also identifies context terms associated with these entities.
- Knowledge panels: Based on these identifications, knowledge panels are generated, providing relevant facts and information about the entity in the context of the search query.
- Ranking and selection: The system assigns rank scores to various knowledge elements based on their relevance to the context terms and selects the most relevant ones for display.
The knowledge panels aim to enhance the user experience by providing more relevant, contextual information directly within search results.
The content of knowledge panels changes dynamically based on the context terms included in the search query. The system uses a sophisticated ranking mechanism to determine the most relevant knowledge elements to display.
This patent emphasizes the evolving nature of search engines toward more contextually aware and user-focused information retrieval, which is crucial for SEO practitioners to understand and adapt to.
SEO implications
- Focus on entity-based optimization: SEO strategies should consider the importance of entities and their context in content creation.
- Rich content creation: Creating content that thoroughly covers entities and their related aspects can increase the chances of being featured in knowledge panels.
- Keyword strategy: Incorporating relevant context terms alongside primary keywords can enhance content visibility.
- Understanding user intent: SEO efforts should align with understanding user intent and the contextual use of search terms.
Get the daily newsletter search marketers rely on.
5. Systems and methods for using document activity logs to train machine-learned models for determining document relevance
- Identifier: US20230267277A1
- Countries: U.S., World Intellectual Property Organization (WIPO)
- Last publishing date: Aug. 24, 2023
(Note: This patent has a pending status. This means it is not used today but could be used in the future.)
User engagement and user logs are important sources for tuning Google’s machine learning algorithms responsible for ranking results. This patent describes techniques for handling this task.
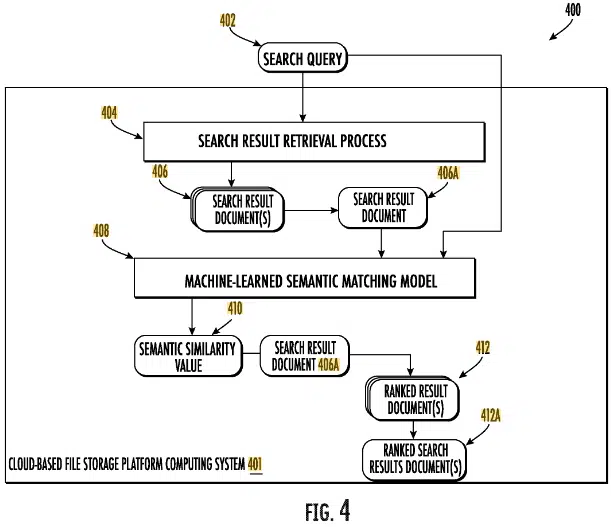
The patent describes systems and methods for training a machine-learned semantic matching model using document activity logs to determine document relevance.
This approach is particularly useful for environments like cloud or private document storage, where access to content or user interaction data is limited.
This method is beneficial when traditional data sources like user interaction data or full document content are unavailable.
Process
- Data collection: Obtain two documents along with their respective activity logs.
- Relation label determination: Based on the activity logs, determine a relation label indicating whether the documents are related.
- Semantic similarity assessment: Input the documents into the model to receive a semantic similarity value, representing the estimated semantic similarity between them.
- Model training: Evaluate a loss function that assesses the difference between the relation label and the semantic similarity value. Modify the model parameters based on this loss function.
Factors
- Document activity logs: These include access timestamps and types of interactions (e.g., editing, sharing).
- Relation labels: Generated based on the time difference between accesses of the documents.
- Semantic similarity value: An output of the model estimating how similar two documents are.
- Loss function: Used to refine the model by comparing the relation label with the semantic similarity value.
SEO implications
- Emphasis on user interaction: SEO strategies might need to focus more on user interaction with documents, as this data can influence document relevance.
- Beyond keywords: Content relevance could be determined by user behaviors and document interactions, not just keywords.
- Private and cloud documents: SEO for private or cloud-stored documents might rely more on how these documents are accessed and used rather than traditional on-page factors.
- Predictive modeling: Understanding and predicting user behavior could become key to SEO strategies.
6. Query composition system
- Identifier: US20230244657A1
- Countries: U.S., China, WIPO, Russia
- Last publishing date: Aug. 3, 2023
(Note: This patent has a pending status. This means it is not used today but could be used in the future.)
Search results are increasingly contextual. Recognizing the context of a query and the user leads to better search results and user experience. This patent is a peace of the puzzle to handle this challenge.
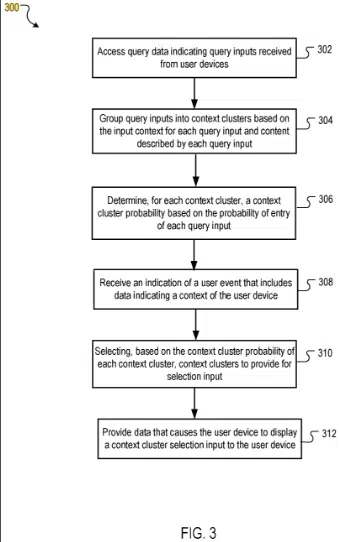
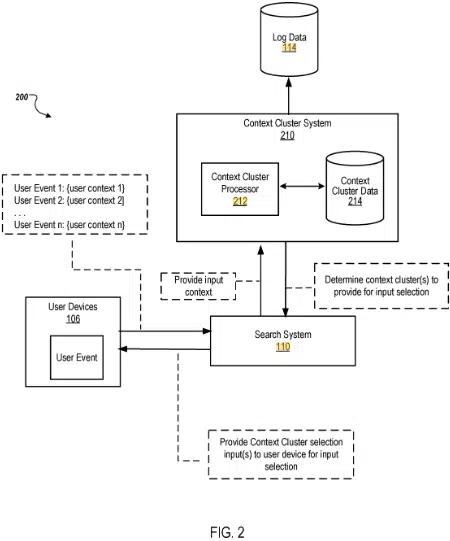
The patent focuses on methods, systems and apparatus for generating data describing context clusters and context cluster probabilities. These clusters are formed based on query inputs and the context associated with each query input.
The patent describes a system that simplifies the search query process using context clusters. These clusters are formed based on the context and content of previous queries.
When a user initiates a search, the system presents relevant context clusters, allowing the user to select a query without typing.
The system aims to enhance the user experience by providing contextually relevant query suggestions without requiring the user to input any characters of the search query.
Process
- Data processing and grouping: The system accesses query data from multiple users, grouping these queries into context clusters based on their input context and content.
- Context cluster probability determination: For each context cluster, a probability is calculated, indicating the likelihood that a query input belonging to that cluster will be selected by a user.
- User event response: Upon indicating a user event (like accessing a search engine), the system selects a context cluster based on the user device’s context and the calculated probabilities.
- Display and selection: The selected context cluster is then displayed to the user for selection, followed by a list of queries within that cluster for further input.
Factors
- Input context: Includes factors like location, date and time, and user preferences.
- Content of query inputs: The actual content described by each query input.
- Context cluster probability: A metric indicating the likelihood of a query input from a cluster being selected by the user.
SEO implications
- Focus on contextual relevance: SEO strategies should prioritize content that aligns with user contexts like location and time.
- Enhanced user intent understanding: Understanding the probable context clusters can help tailor content to match user intent more accurately.
- Adaptation to queryless searches: SEO must adapt to scenarios where users are provided with suggestions before they type any query, emphasizing the importance of being included in relevant context clusters.
7. Combining parameters of multiple search queries that share a line of inquiry
- Identifier: US11762848B2
- Countries: U.S., China
- Last publishing date: September 19, 2023
This patent shows once again how important the individual context of a user is to Google, focusing on enhancing search query processing.
It introduces a method to generate a combined search query based on the parameters of a current search query and one or more previous queries from the same user, provided these queries share a line of inquiry.
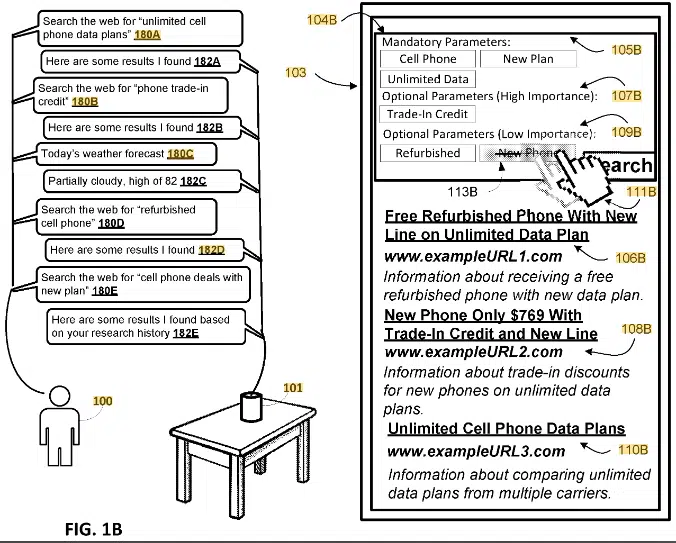
The patent describes a method to streamline online search experiences by intelligently combining multiple related search queries into a single, more effective query.
This approach leverages semantic analysis and user interaction, potentially reducing search results redundancy and enhancing the retrieved information’s relevance.
This patent suggests a significant shift toward a more nuanced, context-aware search process, which could reshape SEO strategies focusing on semantic relevance and user intent.
Process
- Identification of shared line of inquiry: The system identifies when two or more search queries from a user are semantically related and thus share a line of inquiry.
- Combining search queries: Once a shared line of inquiry is established, the system formulates a combined search query incorporating parameters from both the current and previous queries.
- User interaction and feedback: Users can interact with the search parameters or results to refine the combined search query.

Factors
- Semantic similarity: The system uses semantic similarity, measured by embedding queries in latent space and calculating distances between these embeddings, to determine if queries are related.
- Linking grammars and heuristics: The system may also use linking grammars or heuristics to identify related queries, especially in voice search scenarios.
- Stateful research mode: Users may be prompted to enter a stateful research mode, allowing the system to use past queries to formulate combined queries.
SEO implications
- Enhanced focus on semantic relevance: SEO strategies may need to emphasize semantic relevance and context more, as the patent indicates Google’s increasing focus on understanding and linking semantically related queries.
- Long-tail keyword optimization: The ability to combine queries suggests a potential shift toward long-tail keywords and more conversational query formats.
- Content structuring: Content may need to be structured to align seamlessly with a series of related queries, enhancing its chances of being picked up in a combined search scenario.
- Voice search optimization: With the use of linking grammars, optimizing for voice search becomes more crucial, as the system can link spoken queries over time.
8. Presenting search result information
- Identifier: US20230244657A1
- Countries: U.S., China, WIPO, Russia
- Last publishing date: October 3, 2023
At first glance, this patent seems a little confusing, as it discusses using content, mark-ups and annotations from the user’s device. But above all, it shows that search engines such as Google could provide highly personalized search results in the future.
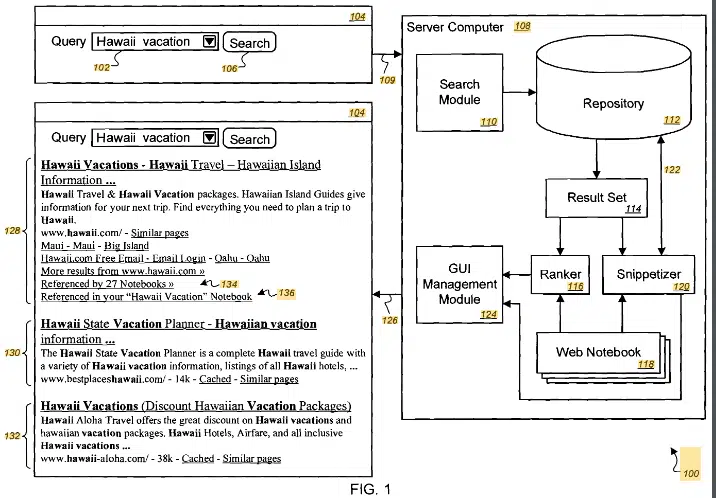
The patent focuses on a method for presenting computer-generated search results. It involves:
- Receiving a search request.
- Identifying multiple search results.
- Ranking these results using content from one or more web notebooks.
- Providing these ranked results for presentation.
The patent describes a method to enhance search result accuracy and relevance by incorporating content from web notebooks.
This approach allows for a more personalized and contextually relevant search experience, as the ranking of search results is influenced by user-generated content and annotations in web notebooks.
Web notebooks, as referenced in the Google patent, are digital collections of content that users create and compile from various web sources. These notebooks can include various content types, such as text excerpts, images and possibly user annotations or metadata.
The key characteristics and uses of web notebooks include:
- Content aggregation: Users clip or select content from different web pages and aggregate this information in a single place. This could be for personal reference, research, or sharing with others.
- User annotations and metadata: In addition to the clipped content, users may add their own annotations, comments, or metadata to the content in these notebooks. This could provide context or personal insights into the collected information.
- Topic-centric collections: Often, web notebooks are centered around specific topics or themes. For instance, users might compile a web notebook about “sustainable gardening practices” or “web development resources.”
- Shareability and accessibility: These notebooks may be private or shared with a select group of users or even made public. This allows for the sharing of curated information and insights.
- Dynamic nature: Unlike static bookmarks, web notebooks can be continually updated and edited, making them a dynamic resource for collecting and organizing web content.
- Search engine integration: As the patent indicates, content within web notebooks can influence search engine results. The search engine might consider the relevance of the content in these notebooks to a particular search query, potentially using them to refine and personalize search results.
Process
- Receiving search request: The method starts by receiving a search request from a client computer.
- Identifying search results: It then identifies a plurality of search results responsive to the request.
- Ranking using web notebooks: The search results are ranked using content in web notebooks. This includes checking if titles, headings, clipped content, metadata, or user annotations in the web notebooks relate to the search request. If so, the ranking of the referenced search results is increased.
- Providing ranked results: Finally, the ranked search results are provided for presentation on the client’s computer.

Factors
- Web notebooks content: The content of web notebooks plays a crucial role in ranking. It includes titles, headings, clipped content, metadata, and user annotations.
- Backlinks analysis: The process may also involve analyzing backlinks corresponding to the search results.
- User identity: The selection of web notebooks for ranking can be based on the user’s identity initiating the search request.
- Snippet information: Generating snippet information by identifying portions of documents in web notebooks associated with the search results is part of the process.
SEO implications
- User-generated content significance: SEO strategies may need to emphasize user-generated content, as web notebooks influence search rankings.
- Personalization and context: There’s a shift toward more personalized and context-aware search results, making it important for SEO to focus on these aspects.
- Diverse content types: Incorporating varied content types like metadata, annotations, and clipped content could become more important for SEO.
9. Multi source extraction and scoring of short query answers
- Identifier: US20230342411A1
- Countries: U.S., Europe, WIPO, South Korea
- Last publishing date: October 26, 2023
The output of direct answers in the SERPs is increasing more and more. An example of this is the information output directly from the Knowledge Graph, featured snippets, and the answers in the Snapshot AI boxes at SGE. This patent shows methods for generating and selecting such direct answers.
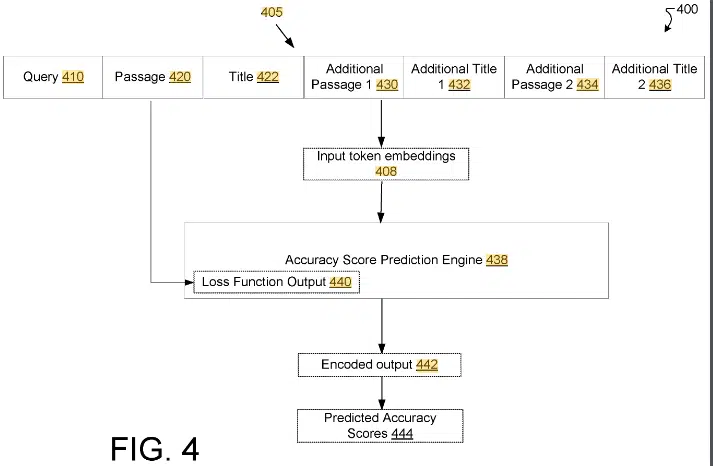
The patent focuses on improving the quality of short answers search engines provide. It introduces a method for generating and scoring these short answers based on multiple sources rather than relying on a single top-ranked search result.
The patent describes a method to enhance the reliability and accuracy of short answers in search engine results. It evaluates a candidate passage against other context passages from different search results, ensuring higher accuracy and relevance.
Process
- Receiving query data: The process begins with the search engine receiving a user’s search query.
- Generating search results: Multiple search results are generated, each containing a passage related to the query.
- Selecting passages: A set of passages is selected, including a candidate passage from a top-ranked search result and additional context passages from other results.
- Scoring candidate passage: The candidate passage is scored using the context passages to produce an accuracy score.
- Display decision: Based on the accuracy score, the candidate passage is either displayed as a short answer in the search results.

Factors
- Accuracy score: The decision to display a short answer is contingent on its accuracy score, which is compared against a predetermined threshold.
- Consensus with context passages: The accuracy score is derived from the degree of consensus between the candidate and context passages.
- Quality of short answer: This multi-source approach enhances the short answer’s quality and reliability.
SEO implications
- This patent suggests a shift toward relevant, contextually accurate and consensus-driven content.
- SEO strategies may need to focus more on providing comprehensive, well-rounded content that aligns with the broader context of a topic rather than just targeting top-ranking keywords or phrases.
- This could lead to a greater emphasis on thorough research, diverse content perspectives, and accuracy in information presented on web pages.
The importance of patents in SEO
Many people start making changes to improve their websites based on “hacks” they find in blogs, social media, YouTube, etc., without really understanding the fundamental principles behind SEO.
That’s why I suggest anyone interested in SEO learn the basics of crawling, indexing and information retrieval.
The next step is to understand the fundamentals of:
Simply looking for practical experience without knowing the scientific principles and understanding the technology often makes us examine things subjectively.
Knowing the technology and the scientific basis is like a rational layer that counter-checks our subjective theories. This way, you are better protected from following every hype.
Google representatives, when talking about Search, only reveal some information, especially regarding how search results are ranked. The details they provide are often vague and unclear. This is intentional, as Google aims to prevent people from manipulating the search results.
Look at other information sources for more in-depth insights. Patent research is a more advanced method. If you’re just starting out, it’s better to stick to the earlier steps.
Regardless of whether a patent makes it into practice, it makes sense to study Google patents because you can get a sense of the issues and challenges that product developers at Google deal with.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.

